
Albanian National Awakening
The Albanian National Awakening or the National Renaissance or the National Revival (Albanian: Rilindja Kombëtare) refers to the period in the history of Albania from 1870 until the Albanian Declaration of Independence in 1912. Its activists are called Revivalists (Albanian: Rilindas).[1][2]
In 1912, with the outbreak of the First Balkan War, the Albanians rose up and declared the creation of an independent Albania, which included what are now Albania and Kosovo.[3] On December 20, 1912 the Conference of Ambassadors in London recognized an independent Albania within its present-day borders.[4]
In 1912, with the outbreak of the First Balkan War, the Albanians rose up and declared the creation of an independent Albania, which included what are now Albania and Kosovo.[3] On December 20, 1912 the Conference of Ambassadors in London recognized an independent Albania within its present-day borders.[4]
Background and 1831–1878 Period
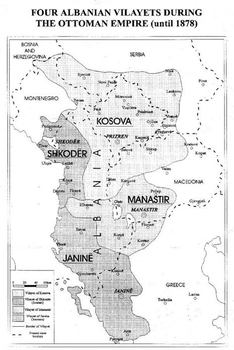 Albanian Villayets under the Ottoman Empire
Albanian Villayets under the Ottoman Empire
Right after 1830, when the Massacre of the Albanian Beys occurred, the last Albanian Pashalik, that of Scutari fell. The Bushati dynasty rule ended when an Ottoman army under Mehmed Reshid Pasha besieged the Rozafa Castle and forced Mustafa Reshiti to surrender (1831).[5] The Albanian defeat ended a planned alliance between the Albanians and the Bosnians, who were similarly seeking autonomy.[6] Instead of the pashalik, the vilayets of Scutari and that of Kosovo were created.
Failed pro-Bushati uprisings in Scutari during 1833–1836 were followed by the northern Albanian Revolt of 1844 and southern Albanian Revolt of 1847, which were reactions to the Ottoman Tanzimat reforms. The 1844 revolt was led by Dervish Cara while 1847 revolt was led by three main leaders: Zenel Gjoleka, Rrapo Hekali and Hodo Nivica. All these uprisings failed; however, they increased the national identity and union between Albanians and played a precursory role to the rise of the Albanian National Awakening.
Failed pro-Bushati uprisings in Scutari during 1833–1836 were followed by the northern Albanian Revolt of 1844 and southern Albanian Revolt of 1847, which were reactions to the Ottoman Tanzimat reforms. The 1844 revolt was led by Dervish Cara while 1847 revolt was led by three main leaders: Zenel Gjoleka, Rrapo Hekali and Hodo Nivica. All these uprisings failed; however, they increased the national identity and union between Albanians and played a precursory role to the rise of the Albanian National Awakening.
Rise of Albanian Nationalism
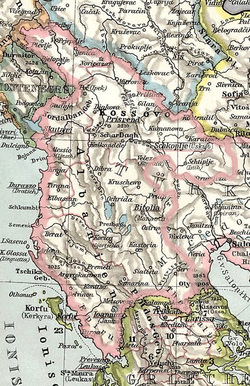 The Albanian territory during the 1800's
The Albanian territory during the 1800's
Because of religious ties of the Albanian majority of the population with the ruling Ottomans and the lack of an Albanian state in past, nationalism was less developed among Albanians in the 19th century than among other southeast European nations. Only from the 1870s and onwards did a movement of ‘national awakening‘ (rilindja) evolve among them - greatly delayed, compared to the Greeks and the Serbs.[1] The 1877–1878 Russo-Turkish War dealt a decisive blow to Ottoman power in the Balkan Peninsula. The Albanians' fear that the lands they inhabited would be partitioned among Montenegro, Serbia, Bulgaria, and Greece fueled the rise of Albanian nationalism. The first postwar treaty, the abortive Treaty of San Stefano signed on March 3, 1878, assigned Albanian-populated lands to Serbia, Montenegro, and Bulgaria. Austria-Hungary and the United Kingdom blocked the arrangement because it awarded Russia a predominant position in the Balkans and thereby upset the European balance of power. A peace conference to settle the dispute was held later in the year in Berlin.[7]
The Treaty of San Stefano triggered profound anxiety among the Albanians meanwhile, and it spurred their leaders to organize a defense of the lands they inhabited. In the spring of 1878, influential Albanians in Constantinople—including Abdyl Frashëri, the Albanian national movement's leading figure during its early years-organized a secret committee to direct the Albanians' resistance. In May the group called for a general meeting of representatives from all the Albanian-populated lands. On June 10, 1878, about eighty delegates, mostly Muslim religious leaders, clan chiefs, and other influential people from the four Albanian-populated Ottoman vilayets, met in the Kosovo city of Prizren. The delegates set up a standing organization, the League of Prizren, under the direction of a central committee that had the power to impose taxes and raise an army. The League of Prizren worked to gain autonomy for the Albanians and to thwart implementation of the Treaty of San Stefano, but not to create an independent Albania.[8]
At first the Ottoman authorities supported the League of Prizren, but the Sublime Porte pressed the delegates to declare themselves to be first and foremost Ottomans rather than Albanians. Some delegates supported this position and advocated emphasizing Muslim solidarity and the defense of Muslim lands, including present-day Bosnia and Herzegovina. Other representatives, under Frashëri's leadership, focused on working toward Albanian autonomy and creating a sense of Albanian identity that would cut across religious and tribal lines.
In July 1878, the league sent a memorandum to the Great Powers at the Congress of Berlin, which was called to settle the unresolved problems of Turkish War, demanding that all Albanians be united in a single autonomous Ottoman province.[10]
The Congress of Berlin ignored the league's memorandum, and Germany's Otto von Bismarck even proclaimed that an Albanian nation did not exist.[11] The congress ceded to Montenegro the cities of Bar and Podgorica and areas around the mountain villages of Gusinje and Plav, which Albanian leaders considered Albanian territory. Serbia also won Albanian-inhabited lands. The Albanians, the vast majority loyal to the empire, vehemently opposed the territorial losses. Albanians also feared the possible loss of Epirus to Greece. The League of Prizren organized armed resistance efforts in Gusinje, Plav, Scutari, Prizren, Preveza, and Ioannina. A border tribesman at the time described the frontier as "floating on blood."[9]
In August 1878, the Congress of Berlin ordered a commission to trace a border between the Ottoman Empire and Montenegro. The congress also directed Greece and the Ottoman Empire to negotiate a solution to their border dispute. The Great Powers expected the Ottomans to ensure that the Albanians would respect the new borders, ignoring that the sultan's military forces were too weak to enforce any settlement and that the Ottomans could only benefit by the Albanians' resistance. The Sublime Porte, in fact, armed the Albanians and allowed them to levy taxes, and when the Ottoman army withdrew from areas awarded to Montenegro under the Treaty of Berlin, Roman Catholic Albanian tribesmen simply took control. The Albanians' successful resistance to the treaty forced the Great Powers to alter the border, returning Gusinje and Plav to the Ottoman Empire and granting Montenegro the mostly Muslim Albanian-populated coastal town of Ulcinj. But the Albanians there refused to surrender as well. Finally, the Great Powers blockaded Ulcinj by sea and pressured the Ottoman authorities to bring the Albanians under control. The Great Powers decided in 1881 to cede Greece only Thessaly and the district of Arta.[12]
Faced with growing international pressure "to pacify" the refractory Albanians, the sultan dispatched a large army under Dervish Turgut Pasha to suppress the League of Prizren and deliver Ulcinj to Montenegro. Albanians loyal to the empire supported the Sublime Porte's military intervention. In April 1881, Dervish Pasha's 10,000 men captured Prizren and later crushed the resistance at Ulcinj. The League of Prizren's leaders and their families were arrested and deported. Frashëri, who originally received a death sentence, was imprisoned until 1885 and exiled until his death seven years later. In the three years it survived, the League of Prizren effectively made the Great Powers aware of the Albanian people and their national interests. Montenegro and Greece received much less Albanian-populated territory than they would have won without the league's resistance.[13]
Formidable barriers frustrated Albanian leaders' efforts to instill in their people an Albanian rather than an Ottoman identity. Divided into four vilayets, Albanians had no common geographical or political nerve center. The Albanians' religious differences forced nationalist leaders to give the national movement a purely secular character that alienated religious leaders. The most significant factor uniting the Albanians, their spoken language, lacked a standard literary form and even a standard alphabet. Each of the three available choices, the Latin, Cyrillic, and Arabic scripts, implied different political and religious orientations opposed by one or another element of the population. In 1878 there were no Albanian-language schools in the most developed of the Albanian-inhabited areas and the choice for education was between Orthodox Church schools, where education was in Greek and Ottoman government schools where education was in Turkish.[14]
Ethnic distribution of Albanians 1898.
The Ottoman Empire continued to crumble after the Congress of Berlin. The empire's financial troubles prevented Sultan Abdül Hamid II from reforming his military, and he resorted to repression to maintain order. The authorities strove without success to control the political situation in the empire's Albanian-populated lands, arresting suspected nationalist activists. When the sultan refused Albanian demands for unification of the four Albanian-populated vilayets, Albanian leaders reorganized the League of Prizren and incited uprisings that brought the Albanian-populated lands, especially Kosovo, to near anarchy. The imperial authorities again disbanded the League of Prizren in 1897, executed its president in 1902, and banned Albanian- language books and correspondence. In Macedonia, where Bulgarian-, Greek-, and Serbian-backed guerrillas were fighting Ottoman authorities and one another for control, Muslim Albanians suffered attacks, and Albanian guerrilla groups retaliated. In 1905 Albanian leaders meeting in Manastir established the Secret Committee for the Liberation of Albania.[15] In September 1906, Albanian patriots assassinated Korçë's Greek Orthodox metropolitan, whose actions had angered the Albanian nationalists.[16]
In 1906 opposition groups in the Ottoman Empire emerged, one of which evolved into the Committee of Union and Progress, more commonly known as the Young Turks, which proposed restoring constitutional government in Constantinople, by revolution if necessary. In July 1908, a month after a Young Turk rebellion in Macedonia supported by an Albanian uprising in Kosovo and Macedonia escalated into widespread insurrection and mutiny within the imperial army, Sultan Abdül Hamid II agreed to demands by the Young Turks to restore constitutional rule. Many Albanians participated in the Young Turks uprising, hoping that it would gain their people autonomy within the empire. The Young Turks lifted the Ottoman ban on Albanian-language schools and on writing the Albanian language. As a consequence, Albanian intellectuals meeting in Bitola in 1908 chose the Latin alphabet as a standard script. The Young Turks, however, were set on maintaining the empire and not interested in making concessions to the myriad nationalist groups within its borders. After securing the abdication of Abdül Hamid II in April 1909, the new authorities levied taxes, outlawed guerrilla groups and nationalist societies, and attempted to extend Constantinople's control over the northern Albanian mountain men. In addition, the Young Turks legalized the bastinado, or beating with a stick, even for misdemeanors, banned carrying rifles, and denied the existence of an Albanian nationality. The new government also appealed for Islamic solidarity to break the Albanians' unity and used the Muslim clergy to try to impose the Arabic alphabet.[17]
The Albanians refused to submit to the Young Turks' campaign to "Ottomanize" them by force. New Albanian uprisings began in Kosovo and the northern mountains in early April 1910. Ottoman forces quashed these rebellions after three months, outlawed Albanian organizations, disarmed entire regions, and closed down schools and publications. Montenegro, preparing to grab Albanian-populated lands for itself, supported a 1911 uprising by the mountain tribes against the Young Turks regime that grew into a widespread revolt. Unable to control the Albanians by force, the Ottoman government granted concessions on schools, military recruitment, and taxation and sanctioned the use of the Latin script for the Albanian language. The government refused, however, to unite the four Albanian-inhabited vilayets.[18]
The Treaty of San Stefano triggered profound anxiety among the Albanians meanwhile, and it spurred their leaders to organize a defense of the lands they inhabited. In the spring of 1878, influential Albanians in Constantinople—including Abdyl Frashëri, the Albanian national movement's leading figure during its early years-organized a secret committee to direct the Albanians' resistance. In May the group called for a general meeting of representatives from all the Albanian-populated lands. On June 10, 1878, about eighty delegates, mostly Muslim religious leaders, clan chiefs, and other influential people from the four Albanian-populated Ottoman vilayets, met in the Kosovo city of Prizren. The delegates set up a standing organization, the League of Prizren, under the direction of a central committee that had the power to impose taxes and raise an army. The League of Prizren worked to gain autonomy for the Albanians and to thwart implementation of the Treaty of San Stefano, but not to create an independent Albania.[8]
At first the Ottoman authorities supported the League of Prizren, but the Sublime Porte pressed the delegates to declare themselves to be first and foremost Ottomans rather than Albanians. Some delegates supported this position and advocated emphasizing Muslim solidarity and the defense of Muslim lands, including present-day Bosnia and Herzegovina. Other representatives, under Frashëri's leadership, focused on working toward Albanian autonomy and creating a sense of Albanian identity that would cut across religious and tribal lines.
In July 1878, the league sent a memorandum to the Great Powers at the Congress of Berlin, which was called to settle the unresolved problems of Turkish War, demanding that all Albanians be united in a single autonomous Ottoman province.[10]
The Congress of Berlin ignored the league's memorandum, and Germany's Otto von Bismarck even proclaimed that an Albanian nation did not exist.[11] The congress ceded to Montenegro the cities of Bar and Podgorica and areas around the mountain villages of Gusinje and Plav, which Albanian leaders considered Albanian territory. Serbia also won Albanian-inhabited lands. The Albanians, the vast majority loyal to the empire, vehemently opposed the territorial losses. Albanians also feared the possible loss of Epirus to Greece. The League of Prizren organized armed resistance efforts in Gusinje, Plav, Scutari, Prizren, Preveza, and Ioannina. A border tribesman at the time described the frontier as "floating on blood."[9]
In August 1878, the Congress of Berlin ordered a commission to trace a border between the Ottoman Empire and Montenegro. The congress also directed Greece and the Ottoman Empire to negotiate a solution to their border dispute. The Great Powers expected the Ottomans to ensure that the Albanians would respect the new borders, ignoring that the sultan's military forces were too weak to enforce any settlement and that the Ottomans could only benefit by the Albanians' resistance. The Sublime Porte, in fact, armed the Albanians and allowed them to levy taxes, and when the Ottoman army withdrew from areas awarded to Montenegro under the Treaty of Berlin, Roman Catholic Albanian tribesmen simply took control. The Albanians' successful resistance to the treaty forced the Great Powers to alter the border, returning Gusinje and Plav to the Ottoman Empire and granting Montenegro the mostly Muslim Albanian-populated coastal town of Ulcinj. But the Albanians there refused to surrender as well. Finally, the Great Powers blockaded Ulcinj by sea and pressured the Ottoman authorities to bring the Albanians under control. The Great Powers decided in 1881 to cede Greece only Thessaly and the district of Arta.[12]
Faced with growing international pressure "to pacify" the refractory Albanians, the sultan dispatched a large army under Dervish Turgut Pasha to suppress the League of Prizren and deliver Ulcinj to Montenegro. Albanians loyal to the empire supported the Sublime Porte's military intervention. In April 1881, Dervish Pasha's 10,000 men captured Prizren and later crushed the resistance at Ulcinj. The League of Prizren's leaders and their families were arrested and deported. Frashëri, who originally received a death sentence, was imprisoned until 1885 and exiled until his death seven years later. In the three years it survived, the League of Prizren effectively made the Great Powers aware of the Albanian people and their national interests. Montenegro and Greece received much less Albanian-populated territory than they would have won without the league's resistance.[13]
Formidable barriers frustrated Albanian leaders' efforts to instill in their people an Albanian rather than an Ottoman identity. Divided into four vilayets, Albanians had no common geographical or political nerve center. The Albanians' religious differences forced nationalist leaders to give the national movement a purely secular character that alienated religious leaders. The most significant factor uniting the Albanians, their spoken language, lacked a standard literary form and even a standard alphabet. Each of the three available choices, the Latin, Cyrillic, and Arabic scripts, implied different political and religious orientations opposed by one or another element of the population. In 1878 there were no Albanian-language schools in the most developed of the Albanian-inhabited areas and the choice for education was between Orthodox Church schools, where education was in Greek and Ottoman government schools where education was in Turkish.[14]
Ethnic distribution of Albanians 1898.
The Ottoman Empire continued to crumble after the Congress of Berlin. The empire's financial troubles prevented Sultan Abdül Hamid II from reforming his military, and he resorted to repression to maintain order. The authorities strove without success to control the political situation in the empire's Albanian-populated lands, arresting suspected nationalist activists. When the sultan refused Albanian demands for unification of the four Albanian-populated vilayets, Albanian leaders reorganized the League of Prizren and incited uprisings that brought the Albanian-populated lands, especially Kosovo, to near anarchy. The imperial authorities again disbanded the League of Prizren in 1897, executed its president in 1902, and banned Albanian- language books and correspondence. In Macedonia, where Bulgarian-, Greek-, and Serbian-backed guerrillas were fighting Ottoman authorities and one another for control, Muslim Albanians suffered attacks, and Albanian guerrilla groups retaliated. In 1905 Albanian leaders meeting in Manastir established the Secret Committee for the Liberation of Albania.[15] In September 1906, Albanian patriots assassinated Korçë's Greek Orthodox metropolitan, whose actions had angered the Albanian nationalists.[16]
In 1906 opposition groups in the Ottoman Empire emerged, one of which evolved into the Committee of Union and Progress, more commonly known as the Young Turks, which proposed restoring constitutional government in Constantinople, by revolution if necessary. In July 1908, a month after a Young Turk rebellion in Macedonia supported by an Albanian uprising in Kosovo and Macedonia escalated into widespread insurrection and mutiny within the imperial army, Sultan Abdül Hamid II agreed to demands by the Young Turks to restore constitutional rule. Many Albanians participated in the Young Turks uprising, hoping that it would gain their people autonomy within the empire. The Young Turks lifted the Ottoman ban on Albanian-language schools and on writing the Albanian language. As a consequence, Albanian intellectuals meeting in Bitola in 1908 chose the Latin alphabet as a standard script. The Young Turks, however, were set on maintaining the empire and not interested in making concessions to the myriad nationalist groups within its borders. After securing the abdication of Abdül Hamid II in April 1909, the new authorities levied taxes, outlawed guerrilla groups and nationalist societies, and attempted to extend Constantinople's control over the northern Albanian mountain men. In addition, the Young Turks legalized the bastinado, or beating with a stick, even for misdemeanors, banned carrying rifles, and denied the existence of an Albanian nationality. The new government also appealed for Islamic solidarity to break the Albanians' unity and used the Muslim clergy to try to impose the Arabic alphabet.[17]
The Albanians refused to submit to the Young Turks' campaign to "Ottomanize" them by force. New Albanian uprisings began in Kosovo and the northern mountains in early April 1910. Ottoman forces quashed these rebellions after three months, outlawed Albanian organizations, disarmed entire regions, and closed down schools and publications. Montenegro, preparing to grab Albanian-populated lands for itself, supported a 1911 uprising by the mountain tribes against the Young Turks regime that grew into a widespread revolt. Unable to control the Albanians by force, the Ottoman government granted concessions on schools, military recruitment, and taxation and sanctioned the use of the Latin script for the Albanian language. The government refused, however, to unite the four Albanian-inhabited vilayets.[18]
Literary revival
Albanian intellectuals in the late nineteenth century began devising a single, standard Albanian literary language and making demands that it be used in schools. In Constantinople in 1879, Sami Frashëri founded a cultural and educational organization, the Society for the Printing of Albanian Writings, whose membership comprised Muslim, Catholic, and Orthodox Albanians. Naim Frashëri, the most-renowned Albanian poet, joined the society and wrote and edited textbooks. Albanian émigrés in Bulgaria, Egypt, Italy, Romania, and the United States supported the society's work. The Greeks, who dominated the education of Orthodox Albanians, joined the Turks in suppressing the Albanians' culture, especially Albanian-language education. In 1886 the ecumenical patriarch of Constantinople threatened to excommunicate anyone found reading or writing Albanian, and priests taught that God would not understand prayers uttered in Albanian.[19]
As was common to the various movements of Romantic nationalism throughout Europe, Albanian intellectuals researched history in an attempt to establish a national identity traced to a people of remote antiquity rather than religion like the neighboring Greeks and Serbs. Such a thing was heavily protested by the Greeks and the Serbs who to this day attempt to suppress historical and archaeological evidence of Albanian insidiousness due to territorial disputes over Kosovo and Epirus. Prime example of this was the assassination of Diaskal Tod'hri, an Albanian orthodox intellectual and albanologist, who was killed by the Greek Church in 1805 for attempting to establish the "Pelasgian Alphabet" as the Albanian one. [31] A most recent case, is the case of Aristithis Kolas, an Arvanite historian from Corinth, Greece; author of such books as: Language of the Gods, Myth and Truth, Arvanite and the Origin of Greeks, provided overwhelming linguistic evidence of the Albanian insidiousness in the Balkans. Kolas, a member of the Marko Botsaris organization, alleged on his death bed in 2000 that just like other members of the same organization who were killed by the Greek government for exposing the truth, he was exposed by government agencies to radiation which lead to his cancer. [32] During her many interviews, Albanologist and professor Elena Kocollari states that a predominate Christian Europe in a desperate attempt to create its own identity, rooted itself in the myth of Ancient Greece and found it hard to credit a small predominate Muslim ethnicity such as the Albanians who at the time where under the Ottoman Empire. She also goes on the state that "Greek ethnicity" is a modern European invention as much of the historical evidence does not support it and that these mistakes are now being admitted by the scientific community but will take time to correct. Even though historians can't all agree on the Albanian-Illyrian connection due to the lack of Pelasgian and Illyrian evidence, they cannot account for their ethnographic and linguistic commonalities to the ancient inhibitors of the Balkan peninsula.
Thus the Illyrian descent theory soon became one of the pillars of Albanian nationalism, especially because it could provide evidence of continuity of Albanian presence both in Kosovo and in southern Albania, i.e. areas that were subjected to ethnic conflicts between Albanians, Serbs and Greeks.[20] Albanians claimed that Alexander the great was [21] Pelasgian - Illyrian - Albanian and that Ancient Greek culture (and thus the result of the spread of Hellenism) had spread [21] by Albanians. [21] Ancient Macedonians were considered forefathers [21] of the Albanians. Ancient Greek gods were seen of "Albanian origin" as well.[22]
The literary revival of the Albanian language had an effect on the distribution of given names in Albania. Traditionally, Albanian given names had universally been Christian, i.e. loaned from Greek hagiography or from the Bible. It was only with the Rilindja that given names were taken from the native Albanian vocabulary. Examples are mostly female given names, such as Lule "flower". This tendency becomes extreme in Communist Albania after 1944, where it was the regime's declared doctrine to oust Christian or Islamic given names. Ideologically acceptable names were listed in the Fjalor me emra njerëzish (1982). These could be native Albanian words like Flutur "butterfly", ideologically communist ones like Proletare, or "Illyrian" ones compiled from epigraphy, e.g. from the necropolis at Dyrrhachion excavated in 1958-60.
As was common to the various movements of Romantic nationalism throughout Europe, Albanian intellectuals researched history in an attempt to establish a national identity traced to a people of remote antiquity rather than religion like the neighboring Greeks and Serbs. Such a thing was heavily protested by the Greeks and the Serbs who to this day attempt to suppress historical and archaeological evidence of Albanian insidiousness due to territorial disputes over Kosovo and Epirus. Prime example of this was the assassination of Diaskal Tod'hri, an Albanian orthodox intellectual and albanologist, who was killed by the Greek Church in 1805 for attempting to establish the "Pelasgian Alphabet" as the Albanian one. [31] A most recent case, is the case of Aristithis Kolas, an Arvanite historian from Corinth, Greece; author of such books as: Language of the Gods, Myth and Truth, Arvanite and the Origin of Greeks, provided overwhelming linguistic evidence of the Albanian insidiousness in the Balkans. Kolas, a member of the Marko Botsaris organization, alleged on his death bed in 2000 that just like other members of the same organization who were killed by the Greek government for exposing the truth, he was exposed by government agencies to radiation which lead to his cancer. [32] During her many interviews, Albanologist and professor Elena Kocollari states that a predominate Christian Europe in a desperate attempt to create its own identity, rooted itself in the myth of Ancient Greece and found it hard to credit a small predominate Muslim ethnicity such as the Albanians who at the time where under the Ottoman Empire. She also goes on the state that "Greek ethnicity" is a modern European invention as much of the historical evidence does not support it and that these mistakes are now being admitted by the scientific community but will take time to correct. Even though historians can't all agree on the Albanian-Illyrian connection due to the lack of Pelasgian and Illyrian evidence, they cannot account for their ethnographic and linguistic commonalities to the ancient inhibitors of the Balkan peninsula.
Thus the Illyrian descent theory soon became one of the pillars of Albanian nationalism, especially because it could provide evidence of continuity of Albanian presence both in Kosovo and in southern Albania, i.e. areas that were subjected to ethnic conflicts between Albanians, Serbs and Greeks.[20] Albanians claimed that Alexander the great was [21] Pelasgian - Illyrian - Albanian and that Ancient Greek culture (and thus the result of the spread of Hellenism) had spread [21] by Albanians. [21] Ancient Macedonians were considered forefathers [21] of the Albanians. Ancient Greek gods were seen of "Albanian origin" as well.[22]
The literary revival of the Albanian language had an effect on the distribution of given names in Albania. Traditionally, Albanian given names had universally been Christian, i.e. loaned from Greek hagiography or from the Bible. It was only with the Rilindja that given names were taken from the native Albanian vocabulary. Examples are mostly female given names, such as Lule "flower". This tendency becomes extreme in Communist Albania after 1944, where it was the regime's declared doctrine to oust Christian or Islamic given names. Ideologically acceptable names were listed in the Fjalor me emra njerëzish (1982). These could be native Albanian words like Flutur "butterfly", ideologically communist ones like Proletare, or "Illyrian" ones compiled from epigraphy, e.g. from the necropolis at Dyrrhachion excavated in 1958-60.
1911 Highlanders Uprising
The rise of Albanian nationalism first sparked with the Battle of Deçiq on April 6, 1911, which was located in the town of Tuzi, Malësi e Madhe. The battle was fought between the Catholic Malësor Albanians led by Ded Gjo Luli, against the forces of the Ottoman Empire led by Turgut Pasha. The long and bloody battle was an Albanian victory. During the battle, the Albanian flag was raised for the first time since George Kastrioti in 1443. As a result of this victory, the Albanians found a sense of confidence and nationalism that led to other events toward independence, which eventually came about on November 28, 1912. Today, many songs and stories of the Albanians are passed in honor of the important battle that led to the independence of Albania.
Albanian Revolt of 1912
The Albanian Revolt of 1912 was one of many Albanian revolts in the Ottoman Empire and lasted from January until August 1912. After a series of successes, Albanian revolutionaries managed to capture the city of Skopje, the administrative centre of Kosovo vilayet within the Ottoman rule.[23][24][25] The revolt ended when the Ottoman government agreed to fulfill the rebels' demands on September 4, 1912.[26] The autonomous system of administration and justice of the four vilayets with the substantial Albanian population, accepted by Ottoman Empire,[27] as autonomous Albanian vilayet was included in the agenda of the Albanian National Awakening during League of Prizren.[28]
Balkan Wars and Creation of Independent Albania
The First Balkan War, however, erupted before a final settlement could be worked out. The Balkan allies—Serbia, Bulgaria, Montenegro and Greece—quickly drove the Ottomans to the walls of Constantinople. The Montenegrins surrounded Scutari.
Ismail Qemali and his cabinet during the celebration of the first anniversary of independence in Vlorë on 28 November 1913.
An assembly of Muslim and Christian leaders meeting in Vlorë in November 1912 declared Albania an independent country and set up a provisional government, but an ambassadorial conference that opened in London in December decided the major questions concerning the Albanians after the First Balkan War in its concluding Treaty of London of May 1913. The Albanian delegation in London was assisted by Aubrey Herbert, MP, a passionate advocate of their cause.
One of Serbia's primary war aims was to gain an Adriatic port, preferably Durrës. Austria-Hungary and Italy opposed giving Serbia an outlet to the Adriatic, which they feared would become a Russian port. They instead supported the creation of an autonomous Albania. Russia backed Serbia's and Montenegro's claims to Albanian-inhabited lands. Britain and Germany remained neutral. Chaired by Britain's foreign secretary, Sir Edward Grey, the ambassadors' conference initially decided to create an autonomous Albania under continued Ottoman rule, but with the protection of the Great Powers. This solution, as detailed in the Treaty of London, was abandoned in the summer of 1913 when it became obvious that the Ottoman Empire would, in the Second Balkan War, lose Macedonia and hence its overland connection with the Albanian-inhabited lands.[29]
In July 1913, the Great Powers opted to recognize an independent, neutral Albanian state ruled by a constitutional monarchy and under the protection of the Great Powers. The August 1913 Treaty of Bucharest established that independent Albania was a country with borders that gave the new state about 28,000 square kilometers of territory and a population of 800,000. Montenegro had to surrender Scutari after having lost 10,000 men in the process of taking the town. Serbia reluctantly succumbed to an ultimatum from Austria-Hungary, Germany, and Italy to withdraw from northern Albania. The treaty, however, left large areas with majority Albanian populations, notably Kosovo and western Macedonia, outside the new state and failed to solve the region's nationality problems.
Recognized borders of Albania.
Territorial disputes have divided the Albanians and Serbs since the Middle Ages, but none more so than the clash over the Kosovo region. Serbs consider Kosovo their Holy Land. They argue that their ancestors settled in the region during the 7th century, that medieval Serbian kings were crowned there, and that the Serbs' greatest medieval ruler, Stefan Dušan, established the seat of his empire for a time near Prizren in the mid-fourteenth century. More important, numerous Serbian Orthodox shrines, including the patriarchate of the Serbian Orthodox Church, are located in Kosovo. The key event in the Serbs' national history, the battle against the Ottoman Turks, took place at Kosovo Polje in 1389. The Albanians, on their part, point to the Illyrian theory of Albanian origins discussed above, as well as to the fact that Prizren was the seat of their first nationalist organization, the League of Prizren, and call the region the cradle of their national awakening. Finally, Albanians claim Kosovo based on their claim that their kinsmen have constituted the vast majority of Kosovo's population since at least the eighteenth century.[30]
When the Great Powers recognized an independent Albania, they also established the International Commission of Control, which endeavored to expand its authority and elbow out the Vlorë provisional government and the rival government of Essad Pasha Toptani, who enjoyed the support of large landowners in central Albania and boasted a formidable militia. The control commission drafted a constitution that provided for a National Assembly of elected local representatives, the heads of the Albanians' major religious groups, ten persons nominated by the prince, and other noteworthy persons.
Ismail Qemali and his cabinet during the celebration of the first anniversary of independence in Vlorë on 28 November 1913.
An assembly of Muslim and Christian leaders meeting in Vlorë in November 1912 declared Albania an independent country and set up a provisional government, but an ambassadorial conference that opened in London in December decided the major questions concerning the Albanians after the First Balkan War in its concluding Treaty of London of May 1913. The Albanian delegation in London was assisted by Aubrey Herbert, MP, a passionate advocate of their cause.
One of Serbia's primary war aims was to gain an Adriatic port, preferably Durrës. Austria-Hungary and Italy opposed giving Serbia an outlet to the Adriatic, which they feared would become a Russian port. They instead supported the creation of an autonomous Albania. Russia backed Serbia's and Montenegro's claims to Albanian-inhabited lands. Britain and Germany remained neutral. Chaired by Britain's foreign secretary, Sir Edward Grey, the ambassadors' conference initially decided to create an autonomous Albania under continued Ottoman rule, but with the protection of the Great Powers. This solution, as detailed in the Treaty of London, was abandoned in the summer of 1913 when it became obvious that the Ottoman Empire would, in the Second Balkan War, lose Macedonia and hence its overland connection with the Albanian-inhabited lands.[29]
In July 1913, the Great Powers opted to recognize an independent, neutral Albanian state ruled by a constitutional monarchy and under the protection of the Great Powers. The August 1913 Treaty of Bucharest established that independent Albania was a country with borders that gave the new state about 28,000 square kilometers of territory and a population of 800,000. Montenegro had to surrender Scutari after having lost 10,000 men in the process of taking the town. Serbia reluctantly succumbed to an ultimatum from Austria-Hungary, Germany, and Italy to withdraw from northern Albania. The treaty, however, left large areas with majority Albanian populations, notably Kosovo and western Macedonia, outside the new state and failed to solve the region's nationality problems.
Recognized borders of Albania.
Territorial disputes have divided the Albanians and Serbs since the Middle Ages, but none more so than the clash over the Kosovo region. Serbs consider Kosovo their Holy Land. They argue that their ancestors settled in the region during the 7th century, that medieval Serbian kings were crowned there, and that the Serbs' greatest medieval ruler, Stefan Dušan, established the seat of his empire for a time near Prizren in the mid-fourteenth century. More important, numerous Serbian Orthodox shrines, including the patriarchate of the Serbian Orthodox Church, are located in Kosovo. The key event in the Serbs' national history, the battle against the Ottoman Turks, took place at Kosovo Polje in 1389. The Albanians, on their part, point to the Illyrian theory of Albanian origins discussed above, as well as to the fact that Prizren was the seat of their first nationalist organization, the League of Prizren, and call the region the cradle of their national awakening. Finally, Albanians claim Kosovo based on their claim that their kinsmen have constituted the vast majority of Kosovo's population since at least the eighteenth century.[30]
When the Great Powers recognized an independent Albania, they also established the International Commission of Control, which endeavored to expand its authority and elbow out the Vlorë provisional government and the rival government of Essad Pasha Toptani, who enjoyed the support of large landowners in central Albania and boasted a formidable militia. The control commission drafted a constitution that provided for a National Assembly of elected local representatives, the heads of the Albanians' major religious groups, ten persons nominated by the prince, and other noteworthy persons.
Also see
References
- Karl Kaser, Frank Kressing. Albania – A country in transition Aspects of changing identities in a south-east European country. Baden-Baden: Nomos-Verlag Extracts, 2002, p. 15
- Hurst, Michael. "7. The Albanian National Awakening, 1878–1912. By Stavro Skendi. Princeton and London: Princeton University Press, 1968. Pp. 498. 110s.". The Historical Journal12 (02): 380. doi:10.1017/S0018246X00004416. Retrieved10 June 2012.
- Sabrina P. Ramet, Serbia, Croatia and Slovenia at peace and at war: selected writings, 1983 - 2007
- Richard C. Hall, The Balkan Wars, 1912-1913: prelude to the First World War
- Vickers, Miranda (1999). The Albanians: a modern history. New York: I. B. Tauris. p. 24. ISBN 978-1-86064-541-9.
- Jelavich, Barbara (1999) [1983]. History of the Balkans: Eighteenth and nineteenth centuries. Cambridge: Cambridge University Press. p. 349. ISBN 978-0-521-27458-6.
- Arthur Bullard,The Diplomacy of the Great War, BiblioBazaar 2009 ISBN 1-110-00529-6, ISBN 978-1-110-00529-1. Length 360 pages
- Leften Stavros Stavrianos, Traian Stoianovich, The Balkans since 1453, Edition 2, C. Hurst & Co. Publishers, 2000 ISBN 1-85065-551-0, ISBN 978-1-85065-551-0 Length 970 pages. page 502
- Helga Turku, Isolationist States in an Interdependent World, Ashgate Publishing, Ltd., 2009 ISBN 0-7546-7932-2,ISBN 978-0-7546-7932-5 Length 182, page 63 ]
- Helga Turku, Isolationist States in an Interdependent World, Ashgate Publishing, Ltd., 2009 ISBN 0-7546-7932-2, ISBN 978-0-7546-7932-5 Length 182 pages, page 63
- Isolationist States in an Interdependent World Author Helga Turku Publisher Ashgate Publishing, Ltd., 2009 ISBN 0-7546-7932-2, ISBN 978-0-7546-7932-5, page 63 (length 182 pages)
- Leften Stavros Stavrianos, Traian Stoianovich, The Balkans since 1453 Edition 2, illustrated Publisher C. Hurst & Co. Publishers, 2000 ISBN 1-85065-551-0, ISBN 978-1-85065-551-0. page 503. Length 970 pages
- Helga Turku, Isolationist States in an Interdependent World, Ashgate Publishing, Ltd., 2009 ISBN 0-7546-7932-2, ISBN 978-0-7546-7932-5, page 64
- Leften Stavros Stavrianos, Traian Stoianovich, The Balkans since 1453 Edition 2, C. Hurst & Co. Publishers, 2000 ISBN 1-85065-551-0, ISBN 978-1-85065-551-0. page 504-505 (Length 970 pages)
- Albania, general information. "8 Nëntori". 1984. p. 33. Retrieved 29 May 2012.
- History of the Balkans: Twentieth century Volume 2 of History of the Balkans, Barbara Jelavich History of the Balkans: Twentieth Century, Barbara Jelavich Volume 12 of Publication series, Joint Committee on Eastern Europe Cambridge paperback library Author Barbara Jelavich Edition illustrated, reprint Publisher Cambridge University Press, 1983 ISBN 0-521-27459-1, ISBN 978-0-521-27459-3 Length 476 pages page 87 link[1]
- Isolationist States in an Interdependent World Author Helga Turku Publisher Ashgate Publishing, Ltd., 2009 ISBN 0-7546-7932-2, ISBN 978-0-7546-7932-5 Length 182 pages page 64 [2]
- History of the Balkans: Twentieth century Volume 2 of History of the Balkans, Barbara Jelavich History of the Balkans: Twentieth Century, Barbara Jelavich Volume 12 of Publication series, Joint Committee on Eastern Europe Cambridge paperback library Author Barbara Jelavich Edition illustrated, reprint Publisher Cambridge University Press, 1983 ISBN 0-521-27459-1, ISBN 978-0-521-27459-3 Length 476 pages page 87-88 link [3]
- Isolationist States in an Interdependent World Author Helga Turku Publisher Ashgate Publishing, Ltd., 2009 ISBN 0-7546-7932-2, ISBN 978-0-7546-7932-5 Length 182 pages page 64 [4]
- Stephanie Schwandner-Sievers, Bernd Jürgen Fischer,Albanian Identities: Myth and History, Indiana University Press, 2002, ISBN 978-0-253-34189-1, p. 118.
- Stephanie Schwandner-Sievers, Bernd Jürgen Fischer, Albanian Identities: Myth and History, Indiana University Press,2002,ISBN 978-0-253-34189-1,page 77
- Stephanie Schwandner-Sievers, Bernd Jürgen Fischer, Albanian Identities: Myth and History, Indiana University Press,2002,ISBN 978-0-253-34189-1,page 77-78
- Bogdanović, Dimitrije (November 2000) [1984]. "Albanski pokreti 1908-1912.". In Antonije Isaković. Knjiga o Kosovu(in Serbian) 2. Belgrade: Serbian Academy of Sciences and Arts. Retrieved January 9, 2011. ustanici su uspeli da slomiju otpor turske armije, da ovladaju celim kosovskim vilajetom do polovine avgusta 1912, što znači da su tada imali u svojim rukama Prištinu, Novi Pazar, Sjenicu pa čak i Skoplje
- Phillips, John (2004). "The rise of Albanian nationalism".Macedonia: warlords and rebels in the Balkans. London: I.B. Tauris. p. 29. ISBN 1-86064-841-X. An Albanian uprising in Kosovo for independent schools in May 1912 led to capture of Skopje by rebels in August
- Bahl, Taru; M.H. Syed (2003). "The Balkan Wars and creation of Independent Albania". Encyclopaedia of the Muslim World. New Delhi: Anmol publications PVT. Ltd. p. 53. ISBN 81-261-1419-3. The Albanians once more raise against Ottoman Empire in May 1912 and took Macedonian capitol of Skopje by August
- Shaw, Stanford J.; Ezel Kural Shaw (2002) [1977]. "Clearing the Decks: Ending the Tripolitanian War and the Albanian Revolt". History of the Ottoman Empire and modern Turkey 2. United Kingdom: The Press Syndicate of University of Cambridge. p. 293. ISBN 0-521-29166-6. Retrieved January 10,2011. Therefore, with only final point being ignored, on September 4, 1912 the government accepted proposals and the Albanian revolt was over
- Shaw, Stanford J.; Ezel Kural Shaw (2002) [1977]. "Clearing the Decks: Ending the Tripolitanian War and the Albanian Revolt". History of the Ottoman Empire and modern Turkey 2. United Kingdom: The Press Syndicate of University of Cambridge. p. 293. ISBN 0-521-29166-6. Retrieved January 10,2011.
- Kopeček, Michal, Discourses of collective identity in Central and Southeast Europe (1770-1945) 2, Budapest, Hungary: Central European University Press, ISBN 963-7326-60-X, retrieved January 18, 2011, Soon after this first meeting,....mainly under the influence of ... Abdyl Frashëri ... new agenda included ... the fonding of an autonomous Albanian Vilayet
- History of the Balkans: Twentieth century Volume 2 of History of the Balkans, Barbara Jelavich History of the Balkans: Twentieth Century, Barbara Jelavich Volume 12 of Publication series, Joint Committee on Eastern Europe Cambridge paperback library Author Barbara Jelavich Edition illustrated, reprint Publisher Cambridge University Press, 1983 ISBN 0-521-27459-1, ISBN 978-0-521-27459-3 Length 476 pages page 87 link
- See the ethnic composition maps of the Balkans in the Treaty of San Stefano article, and Di Lellio, Anna (2006) The case for Kosova: passage to independence Anthem Press, London, page 19, ISBN 1-84331-245-X; See also Kosovo population data-points